深入 NVIDIA GPU:高性能矩阵乘法(Matmul)算子解构在本篇博文中,我将逐步介绍支撑最尖端(SOTA)NVIDIA GPU 矩阵乘法(matmul)算子...

倒计时 1 天,Meet AI Compiler 第 8 期将于明天(12 月 27 日)在上海开讲! HyperAI超神经邀请了来自上海创智学院、TileAI 社区、华为...

随着大语言模型(LLM)的迅速发展,AI 不再只是“会聊天”的工具,而是能够理解、推理并生成多模态内容的智能体。本文将基于Orion O6平台...

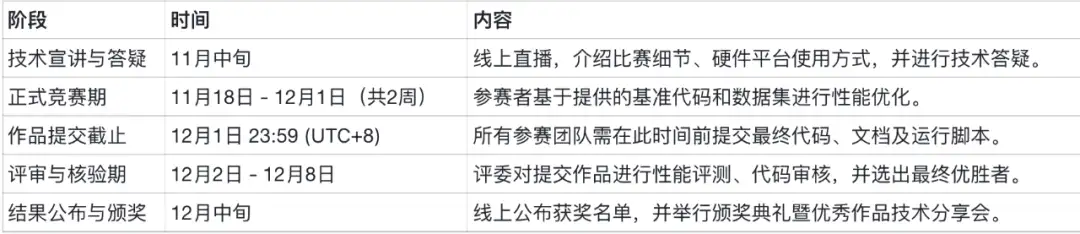
在大模型与高性能计算深度融合的当下,充分释放GPU硬件算力已成为推动技术进步的关键环节。为探索GPU性能优化的前沿技术,培养高水平计...
首先非常感谢极术社区和arm china提供的这次试用机会!目前,端侧 AI 部署已成为行业发展的重要趋势。随着大语言模型(LLM)和多模态模...










