在 Part 1 中,我们通过 for 循环构建了 MoE 计算的基准模型。这种“专家视角”的实现虽然逻辑清晰,但在执行层面会产生大量细粒度的算子调用(Kernel Launch),增加了系统调度开销,难以充分利用 GPU 的并行计算能力。(参考:从循环到融合:理解 Fused MoE 算子原理(一))

设立这一系列的初衷,是为了更透明地分享达坦科技开源项目的成长轨迹。在这里,我们不仅会同步项目近期的核心开发进展与技术突破,更将通过路线图为您揭示未来的演进方向。
深入 NVIDIA GPU:高性能矩阵乘法(Matmul)算子解构在本篇博文中,我将逐步介绍支撑最尖端(SOTA)NVIDIA GPU 矩阵乘法(matmul)算子的核心硬件概念和编程技术。

混合专家(Mixtureof Experts, MoE)作为大模型高效训练与推理的核心架构,其专家筛选环节的性能瓶颈直接制约整体系统效率。DeepSeek开源的分组式Top-K专家选择逻辑,虽在算法层面实现了专家筛选的合理性,但基于PyTorch的原生实现在通用计算架构下存在显著性能损耗,单次专家筛选操作耗时高达100微秒(μs),成为MoE推...
设立这一系列的初衷,是为了更透明地分享达坦科技开源项目的成长轨迹。在这里,我们不仅会同步项目近期的核心开发进展与技术突破,更将通过路线图为您揭示未来的演进方向。
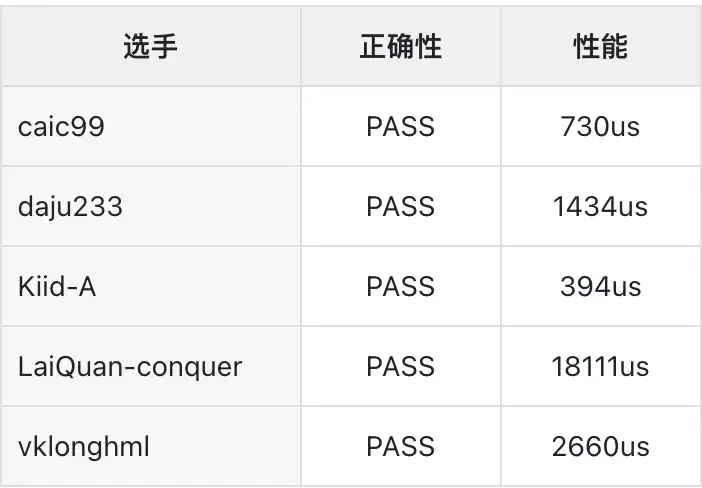
自达坦科技GPU性能优化挑战赛启动以来,我们收到了众多技术爱好者的热烈响应与精彩提交。近日,随着公示期的圆满结束,我们正式公布本次大赛的最终获奖名单!
历时数周的激烈角逐,2025 DatenLord GPU 性能优化大赛已圆满落幕!本次大赛吸引了来自全国众多高校学生与开发者的积极参与,涌现了大量优秀的GPU内核优化方案,展现了大家在高性能计算领域的深厚功底与创新思维。
在当今大语言模型(LLM)的浪潮中,模型规模的持续扩张是提升性能的关键驱动力。然而,随着模型参数量的激增,训练和推理的计算成本也随之飙升。为了解决这一挑战,混合专家模型(Mixture-of-Experts, MoE)架构应运而生,并已成为许多前沿模型(如 Mixtral 8x7B, DeepSeek-V3)的核心技术之一。
在AI基础设施飞速发展的今天,培养具备GPU计算能力的专业人才成为行业迫切需求。达坦科技联合琶洲实验室(黄埔)推出的「开源组会」系列活动正是这一背景下的创新实践,为AI Infra领域的人才培养开辟了新路径。
达坦科技始终致力于打造高性能AI+Cloud基础设施平台,积极推动AI应用的落地。达坦科技通过软硬件深度融合的方式,提供AI推理引擎和高性能网络,为AI应用提供弹性、便利、经济的基础设施服务,以此满足不同行业客户对AI+Cloud的需求。在本周的前沿技术分享中,我们邀请到了中国科学院大学在读学生许佳凯,来为大家分享从 ...
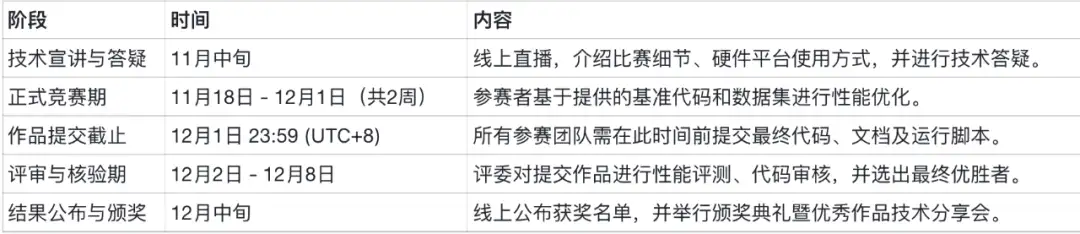
在大模型与高性能计算深度融合的当下,充分释放GPU硬件算力已成为推动技术进步的关键环节。为探索GPU性能优化的前沿技术,培养高水平计算人才,达坦科技在2025年11月份举办 “GPU性能优化比赛” ,现正式启动赛事报名工作。
近日,由意大利国家核物理研究所(INFN)主导的国际天文观测研究团队,在切伦科夫望远镜阵列(Cherenkov Telescope Array Observatory, CTAO)项目中取得了重要突破,其最新研究成果已正式发表在《IEEE Transactions on Nuclear Science》这一期刊。
在大模型时代,对极致性能的追求永无止境。作为一门为大规模并行计算而生的高性能语言,Triton 正凭借其出色的开发效率和接近硬件极限的性能,受到越来越多AI工程师的关注。在达坦科技,我们也在积极拥抱 Triton,利用它来开发和优化GPU算子,以加速大模型的推理效率。
达坦科技始终致力于打造高性能AI+Cloud基础设施平台,积极推动AI应用的落地。达坦科技通过软硬件深度融合的方式,提供AI推理引擎和高性能网络,为AI应用提供弹性、便利、经济的基础设施服务,以此满足不同行业客户对AI+Cloud的需求。在本周的前沿技术分享中,我们邀请到了软硬件联合开发工程师陈添,来为大家分享Triton ...
2025年,全球开源芯片开放架构技术的盛会——第五届RISC-V中国峰会将于7月16日至19日上海张江科学会堂盛大召开。本届中国峰会将聚焦人工智能、高性能计算、汽车电子、软件与生态系统、教育与人才培养、前沿技术创新、EDA、投资与并购等九大热门话题,采用“主论坛+专题研讨+生态展览+开发者活动”的多元形式,汇聚全球顶尖专...

在 《虚拟 RDMA 设备驱动实现(一):环境配置与Linux内核模块初探》 中,我们已经完成了内核驱动开发所需的基础设施构建。通过部署一个标准化的虚拟化开发环境,并实践了 out-of-tree 内核模块的完整生命周期,我们确立了在内核空间执行自定义代码的基本能力。
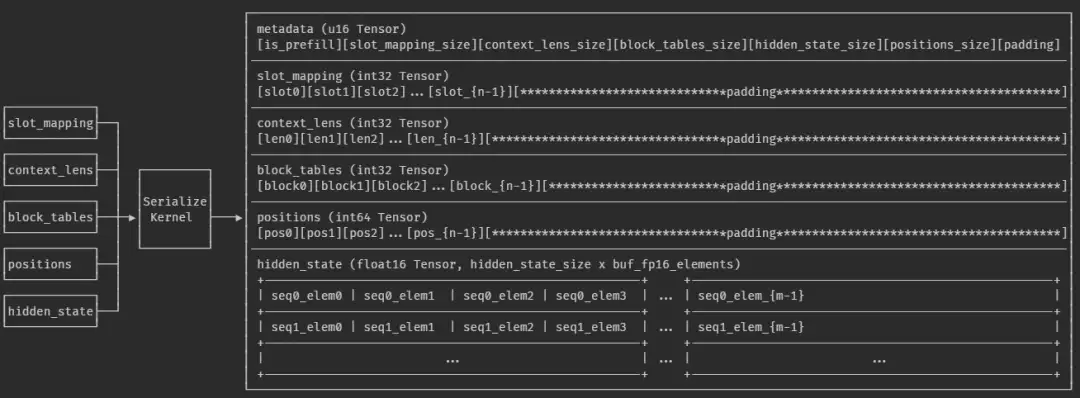
在当今数据以前所未有的速度和规模产生、传输和处理的时代,系统性能的每一个环节都面临着极致的考验。从高性能计算集群到大规模分布式存储,从实时金融交易到低延迟的云服务,对高效数据交换的需求日益迫切。然而,传统的网络通信方式,尽管成熟稳定,其固有的处理开销和多次数据拷贝,在这些追求极致性能的场景下,往...
鹏城实验室与琶洲实验室(黄埔)作为国内顶尖的科研机构,长期致力于人工智能、高性能计算及信息科学领域的前沿探索。鹏城实验室聚焦智能技术与系统创新,琶洲实验室(黄埔)则依托粤港澳大湾区区位优势,深耕网络通信与硬件研发,两者共同推动产学研深度融合。
达坦科技即将开源的100G RDMA RTL代码采用cocotb对其功能进行验证。其中,对于DMA引擎的验证工作使用了开源的cocotbext-pcie框架来进行验证。本文将简要介绍cocotbext-pcie的使用方式,以及在使用中遇到的问题。
blue-rdma是一个新的RDMA实现。本文将介绍blue-rdma是如何实现常见的几种RDMA操作的,并且我们会分析blue-rdma设计和InfiniBand的异同点。


