Spectron是谷歌Research和Verily AI开发的新的模型。与传统的语言模型不同,Spectron直接处理频谱图作为输入和输出。该模型消除归纳偏差...
抽样是研究和数据收集中不可或缺的方法,能够从更大数据中获得有意义的见解并做出明智的决定的子集。不同的研究领域采用了不同的抽样技...
生物信息学 (Bioinformatics) 是指利用应用数学、信息学、统计学和计算机科学的方法,研究生物学问题。随着计算机科学技术的发展,AI 在...

随着物流订单达到新的量级,传统物流运输过程无法实时监控与管理,同时人力作业也难以保证其效率,容易出现各种意外风险,因此仓储物流...

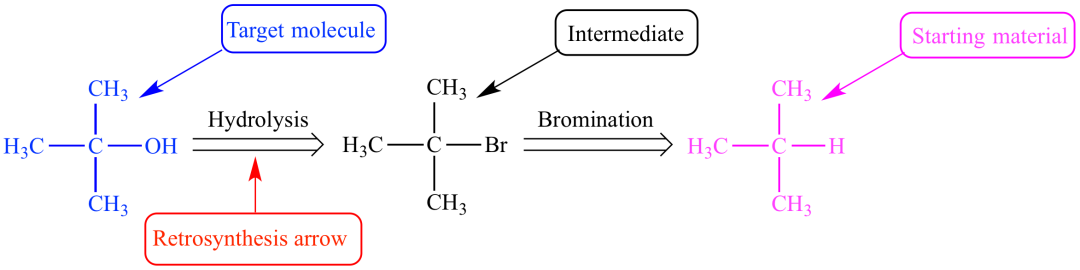
逆合成旨在找到一系列合适的反应物,以高效合成目标产物。这是解决有机合成路线的重要方法,也是有机合成路线设计的最简单、最基本的方...
生物传感是人类与机器、人类与环境、机器与环境交互的重要媒介。其中,触觉能够实现精准的环境感知,帮助使用者与复杂环境交互。 为模仿...

可视化是一种强大的工具,用于以直观和可理解的方式传达复杂的数据模式和关系。它们在数据分析中发挥着至关重要的作用,提供了通常难以...
机器学习与深度学习的应用已广泛渗透到各个行业和领域中,但随之而来的计算复杂性和时间耗费也日益增加。如何有效地优化和加速这些计算...

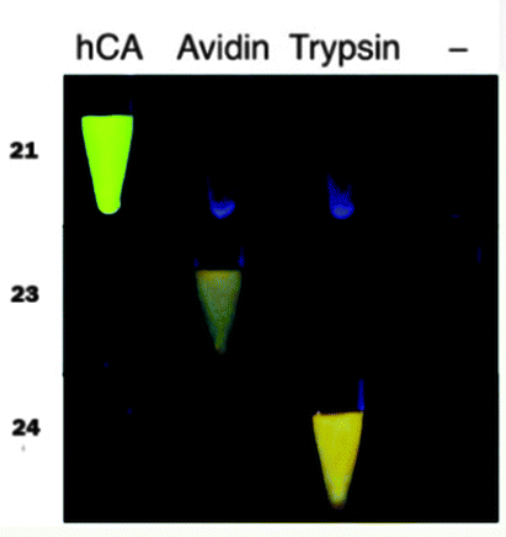
多肽是两个以上氨基酸通过肽键组成的生物活性物质,可以通过折叠、螺旋形成更高级的蛋白质结构。多肽不仅与多个生理活动相关联,还可以...
自从扩散模型发布以来,GAN的关注度和论文是越来越少了,但是它们里面的一些思路还是值得我们了解和学习。所以本文我们来使用Pytorch 来...
如果沿着y轴移动序列添加随机噪声,并随机化这些序列,那么它们几乎无法分辨,如下图所示-现在很难将时间序列列分组为簇:
据世界卫生组织统计,全球共 22 亿人视力受损,包含 2.85 亿视障人群和 3,900 万全盲人群。而且,这一数字将随老龄化加剧不断增加。 虽...

相似性度量在机器学习中起着至关重要的作用。这些度量以数学方式量化对象、数据点或向量之间的相似性。理解向量空间中的相似性概念并采...
星系中的异常现象是我们了解宇宙的关键。然而,随着天文观测技术的发展,天文数据正以指数级别增长,超出了天文工作者的分析能力。尽管...

随着数据集的规模和复杂性的增长,特征或维度的数量往往变得难以处理,导致计算需求增加,潜在的过拟合和模型可解释性降低。降维技术提...
XGBoost是处理不同类型表格数据的最著名的算法,LightGBM 和Catboost也是为了修改他的缺陷而发布的。9月12日XGBoost发布了新的2.0版,本...
本文为2023年第十八届中国研究生电子设计竞赛兆易创新企业命题全国三等奖以,参加极术社区的【有奖活动】分享2023研电赛作品扩大影响力...

高斯混合模型(Gaussian Mixture Models,简称GMM)是一种在统计和机器学习领域中常用的概率模型,用于对复杂数据分布进行建模和分析。G...
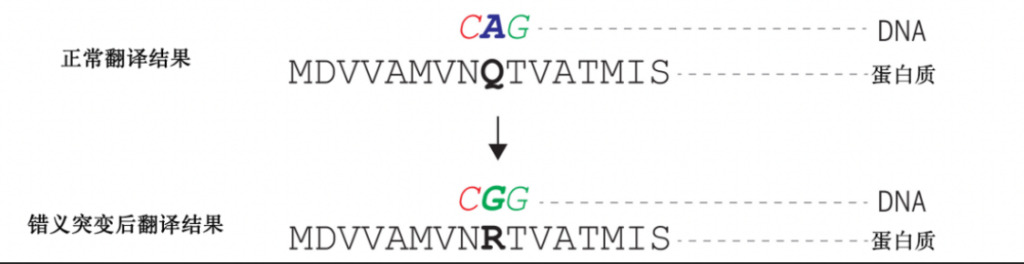
类基因组共有 31.6 亿个碱基对,无时无刻不在经历复制、转录和翻译,也随时有着出错突变的风险。错义突变是基因突变中的一种常见形式,...
这是一篇很有意思的论文,他基于心音信号的对数谱图,提出了两种心率音分类模型,我们都知道:频谱图在语音识别上是广泛应用的,这篇论...






