本篇文章译自英文文档 Compile ONNX Models — tvm 0.13.dev0 documentation作者是 Joshua Z. Zhang更多 TVM 中文文档可访问 →TVM 中文站...
在嵌入式领域,代码体积(code size)优化能够减少内存的使用,对产品的竞争力至关重要。对当代产品而言, code size优化可以为产品放入...

LLVM 16于2022年3月17日发布([链接])。和往常一样,Arm增加了对新架构和CPU的支持,并显著提高了性能。这一次,我们还带来了令人兴奋的...

Claude在MLIR代码分析上完全超越了ChatGPT并表现十分惊艳,请阅读全文或者自己注册感受它的强大。结论:在本文的任务中,Claude > Ch...

编译器中的多面体模型(polyhedral model)是一种高效的程序优化技术,它将复杂的循环依赖关系映射到高维几何空间,从而在编译阶段实现...

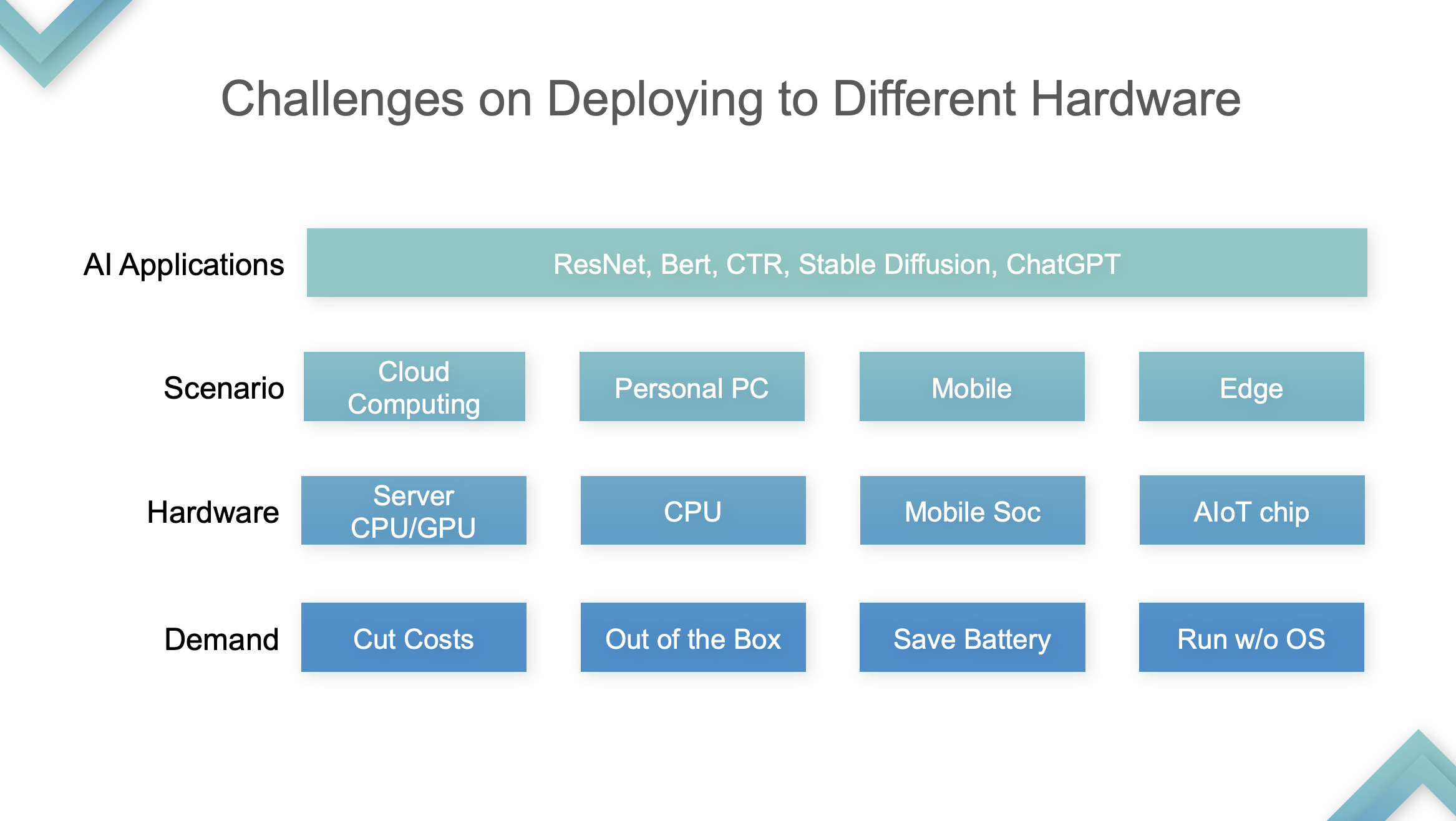
DSA 编译器解决的本质问题就是不同的模型需要部署到硬件上,利用各种抽象层级的优化手段,使得模型尽量打满芯片,也就是要压缩气泡。关...

本次分享来自遇见未来系列讲座——与曾建江老师探讨AIOT时代的编程语言、编译器与指令集架构:机遇、挑战与展望。编译器、编程语言以及指...

本篇文章译自英文文档 Quick Start Tutorial for Compiling Deep Learning Models 作者是 Yao Wang,Truman Tian。更多 TVM 中文文档可访...
我们经常会好奇,我启动了一个 JVM,他到底会占据多大的内存?他的内存都消耗在哪里?为什么 JVM 使用的内存比我设置的 -Xmx 大这么多?...

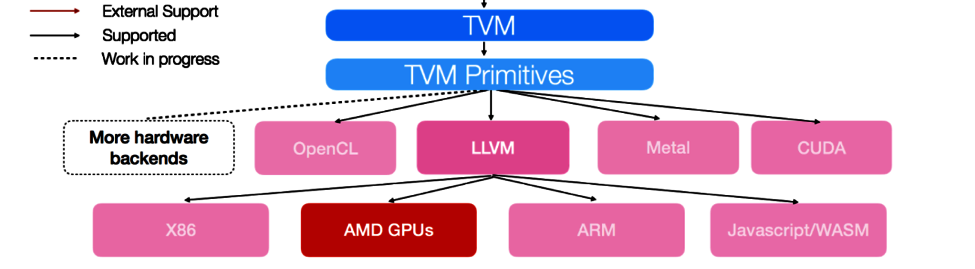
内容一览:本文整理自 Apache TVM PMC、上海交通大学博士生冯思远在 2023 Meet TVM 上海站的演讲分享,主题为「TVM 与机器学习编译发展...
指令调度是指对程序块或过程中的操作进行排序以有效利用处理器资源的任务[1]。指令调度的目的就是通过重排指令,提高指令级并行性,使得...

软件开发人员往往期望计算机硬件拥有无限容量、零访问延迟、无限带宽以及便宜的内存,但是现实却是内存容量越大,相应的访问时间越长;...

本文首发自微信公众号:HyperAI超神经内容一览:「2023 Meet TVM·开年首聚」成功线下相聚上海,来自企业和高校的 100 多位参与者齐聚一...

别名分析是编译器理论中的一种技术,用于确定存储位置是否可以以多种方式访问。如果两个指针指向相同的位置,则称这两个指针为别名。但...

概念介绍在介绍算法之前,我们回顾下基本概念:|X|:X的度数,(无向图中)节点的邻居个数。CFG:控制流图。successor:本文指CFG中基本块...

本篇文章译自英文文档 Cross Compilation and RPC 作者是 Ziheng Jiang,Lianmin Zheng。更多 TVM 中文文档可访问 →TVM 中文站
定义 loop(llvm里理解为natural loop)是定义在CFG中的一个结点集合L,并具有以下属性[1][2]:

内容一览:从去年 12 月延期至今的 TVM 线下聚会终于来了!首站地点我们选在了上海,并邀请到了 4 位讲师结合自己的工作实践,分享 TVM ...
下图给出的简要程序流图中, ①是我们想要优化的代码,②和③是优化后的代码,让我们先思考下面几个问题:

基本块 (Basic Block) 一个基本块内的指令,处理器会从基本块的第一条指令顺序执行到基本块的最后一条指令,中间不会跳转到其它地方去,...








