内容一览: 鲍曼不动杆菌是一种常见的医院获得性革兰氏阴性病原体,通常表现出多重耐药性。利用传统方法,发现抑制此菌的新型抗生素很困...

这是新加坡国立大学在2022 aaai发布的一篇论文。WideNet是一种参数有效的框架,它的方向是更宽而不是更深。通过混合专家(MoE)代替前馈网...
levi - unet[2]是一种新的医学图像分割架构,它使用transformer 作为编码器,这使得它能够更有效地学习远程依赖关系。levi - unet[2]比...
18大数据挖掘的经典算法以及代码实现,涉及到了决策分类,聚类,链接挖掘,关联挖掘,模式挖掘等等方面,后面都是相应算法的博文链接,希...

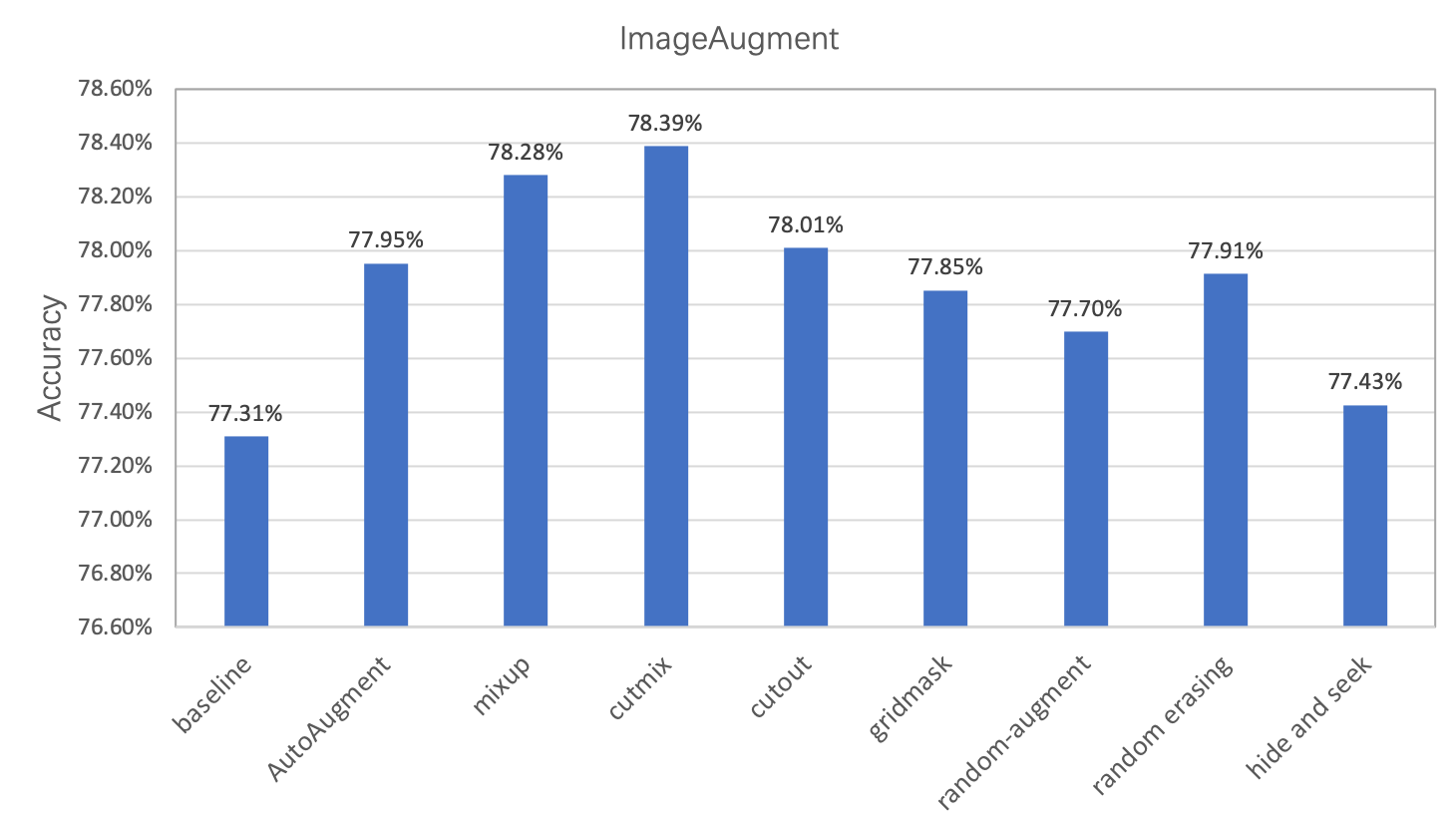
在图像分类任务中,图像数据的增广是一种常用的正则化方法,主要用于增加训练数据集,让数据集尽可能的多样化,使得训练的模型具有更强...
人工智能领域:面试常见问题超全(深度学习基础、卷积模型、对抗神经网络、预训练模型、计算机视觉、自然语言处理、推荐系统、模型压缩...
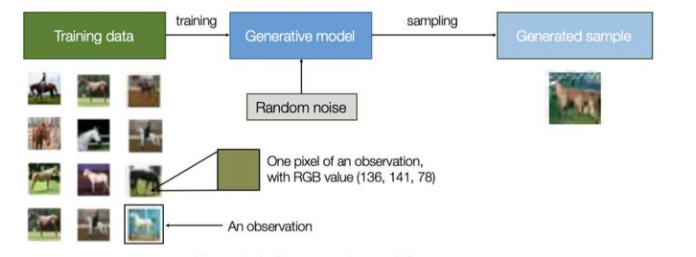
所谓生成模型,就是指可以描述成一个生成数据的模型,属于一种概率模型。维基百科上对其的定义是:在概率统计理论中, 生成模型是指能...
这时一篇2015年的论文,但是他却是最早提出在语义分割中使用弱监督和半监督的方法,SAM的火爆证明了弱监督和半监督的学习方法也可以用在...
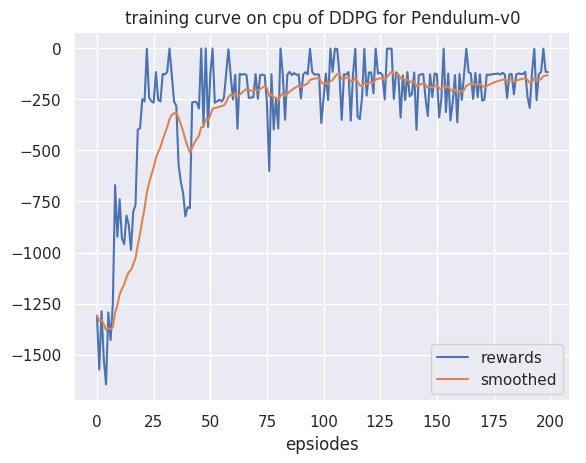
OpenAI Gym中其实集成了很多强化学习环境,足够大家学习了,但是在做强化学习的应用中免不了要自己创建环境,比如在本项目中其实不太好...
内容一览: 基因渐渗与葡萄的驯化、遗传改良密切相关。先前研究揭示了欧洲栽培葡萄中,野生葡萄基因渐渗的基因组信号,但尚未深入研究这...

在过去的几个月里,大型语言模型(llm)获得了极大的关注,这些模型创造了令人兴奋的前景,特别是对于从事聊天机器人、个人助理和内容创作...
优势演员-评论员(advantage actor-critic,A2C)算法:一种改进的演员-评论员(actor-critic)算法。
理性这个关键字,因为它是博弈论的基础。我们可以简单地把理性称为一种理解,即每个行为人都知道所有其他行为人都和他/她一样理性,拥有...
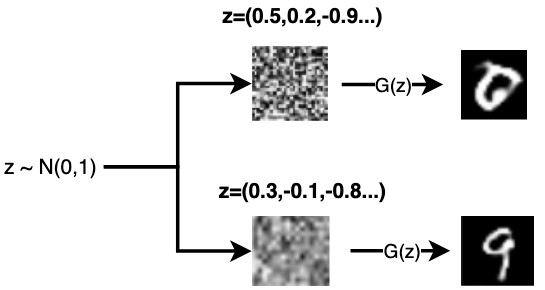
深度Q网络(deep Q-network,DQN):基于深度学习的Q学习算法,其结合了价值函数近似(value function approximation)与神经网络技术,...
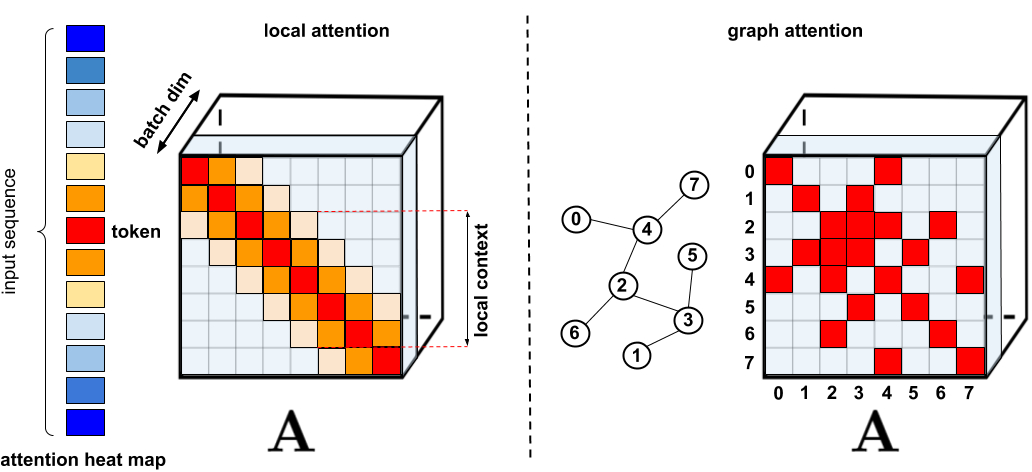
基于Transformer模型在众多领域已取得卓越成果,包括自然语言、图像甚至是音乐。然而,Transformer架构一直以来为人所诟病的是其注意力...
当身边的人都在讨论大模型时,你有没有发现总会听到一些陌生的词汇?这个视频通过通俗易懂的例子带你轻松了解这些大模型的行业黑话,看...

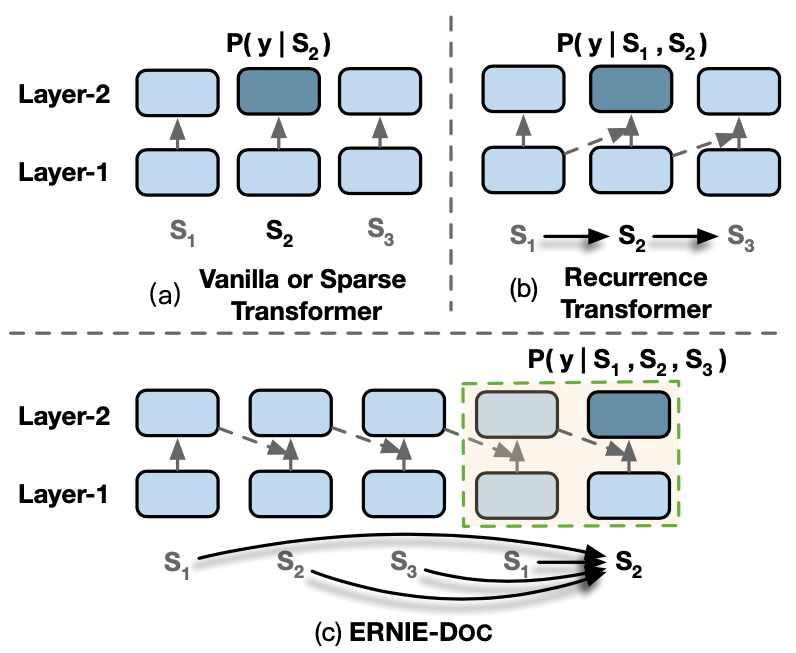
经典的Transformer在处理数据时,会将文本数据按照固定长度进行截断,这个看起来比较”武断”的操作会造成上下文碎片化以及无法建模更长的...
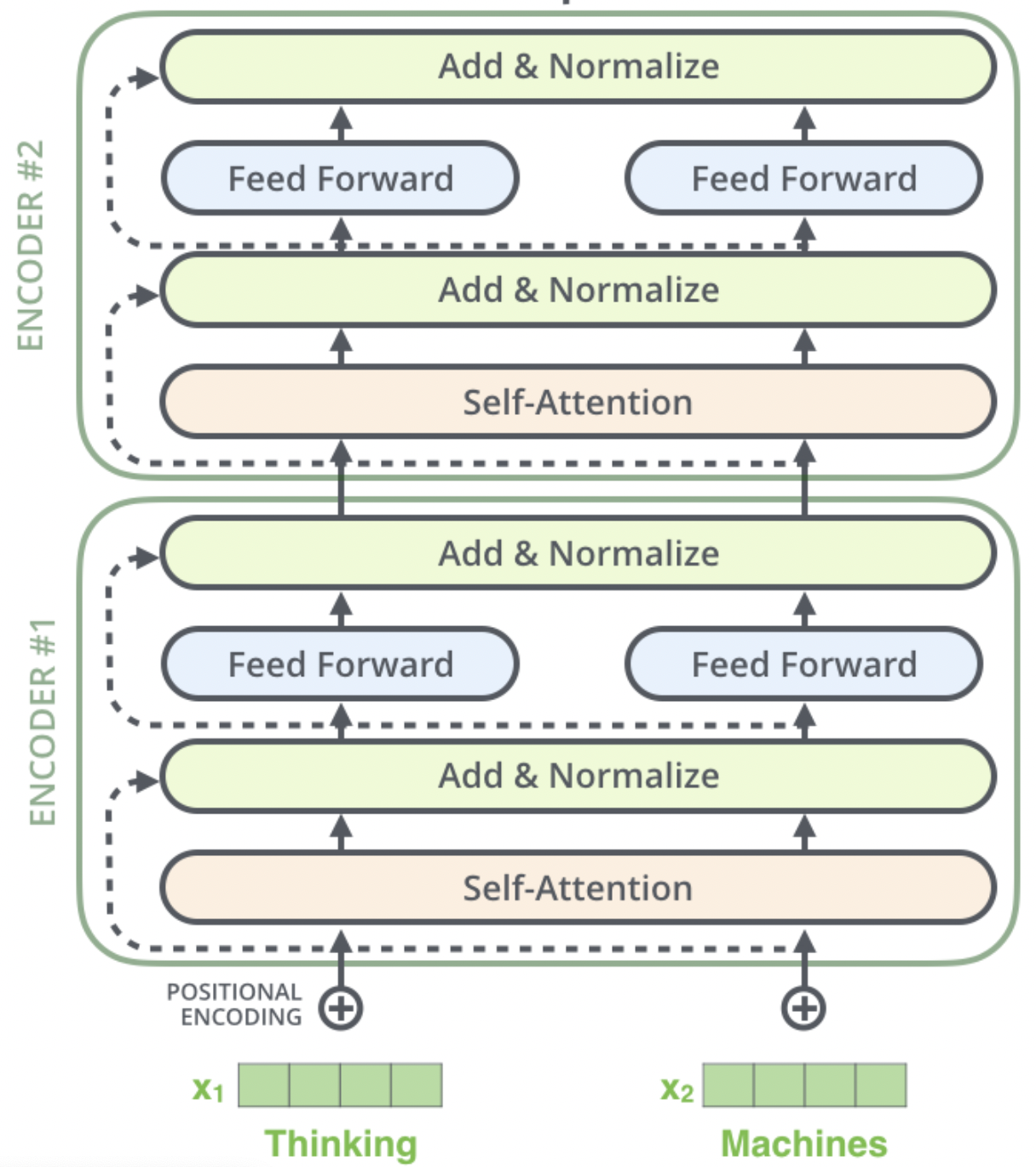
ERINE是百度发布一个预训练模型,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务上超越了BERT。在模型结构方...
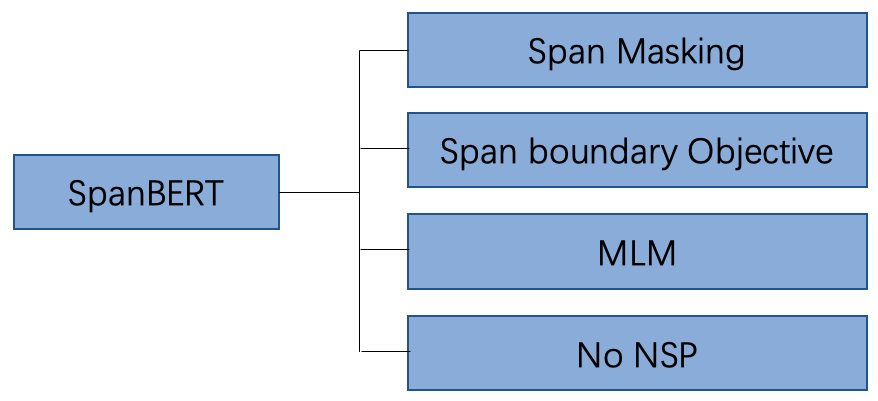
深度学习进阶篇-预训练模型[4]:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解1.SpanBERT: Improving ...
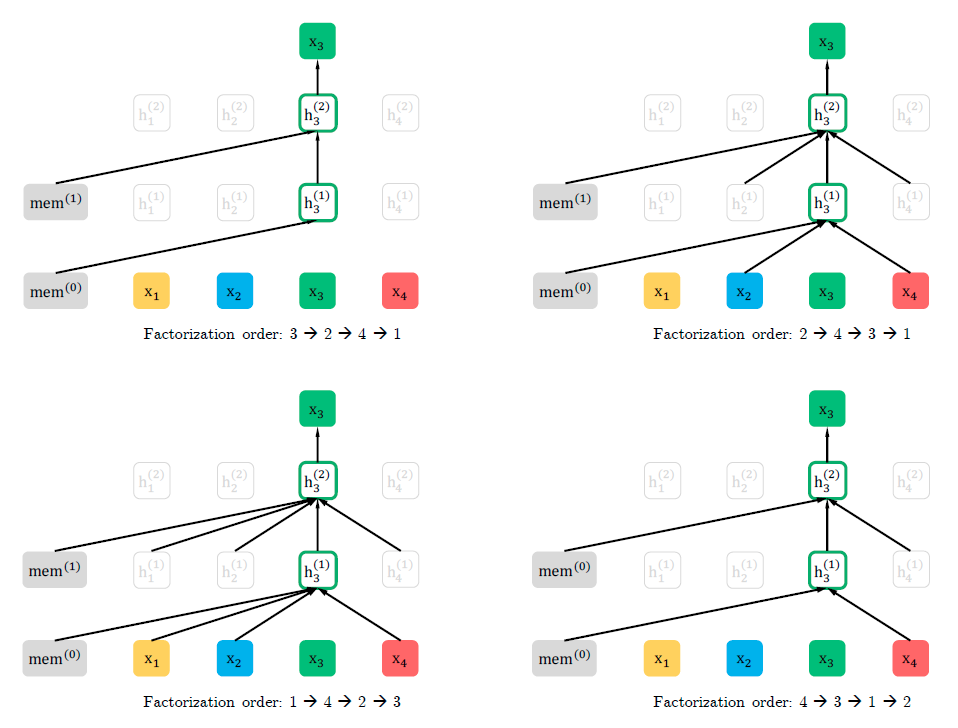
自回归模型(Autoregressive Model, AR),通过估计一串文本序列的生成概率分布进行建模。一般而言,AR模型通过要么从前到后计算文本序...