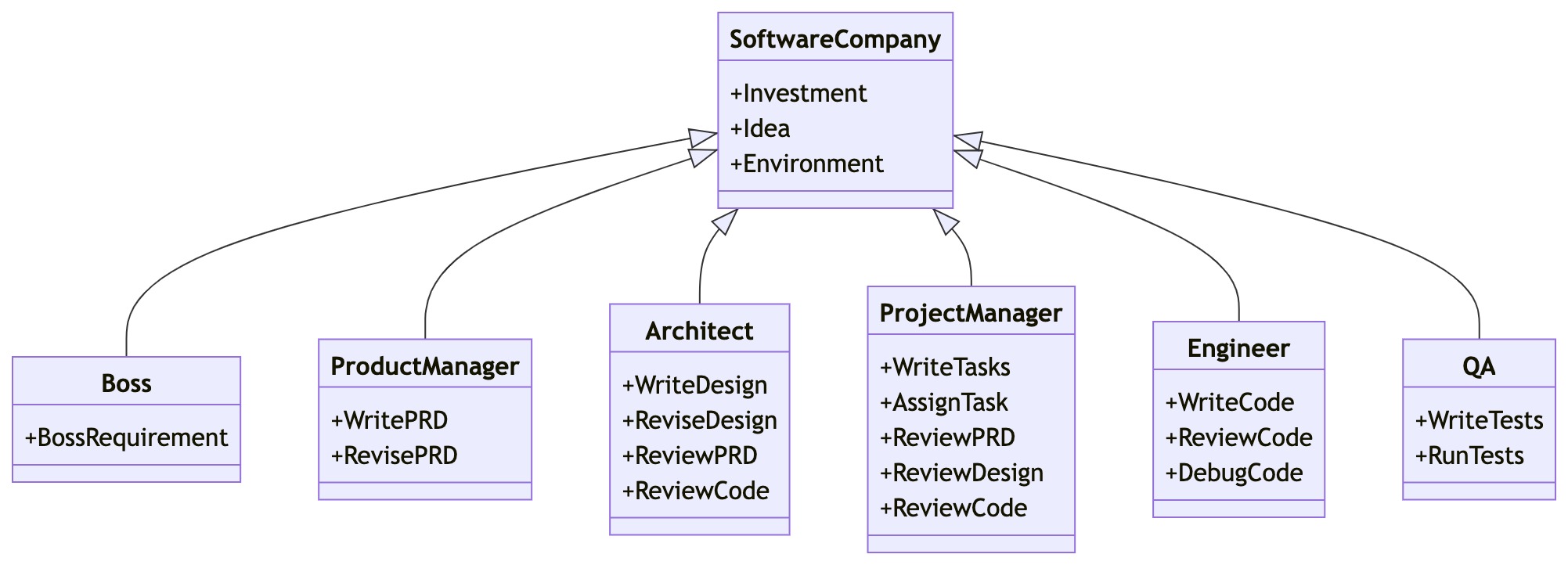
今天要介绍的 Elasticsearch Relevance Engine™ (ESRE™),提供了多项用于创建高度相关的 AI 搜索应用程序的新功能。ESRE 站在 Elastic ...
这是谷歌在9月最近发布的一种新的架构 TSMixer: An all-MLP architecture for time series forecasting ,TSMixer是一种先进的多元模型...
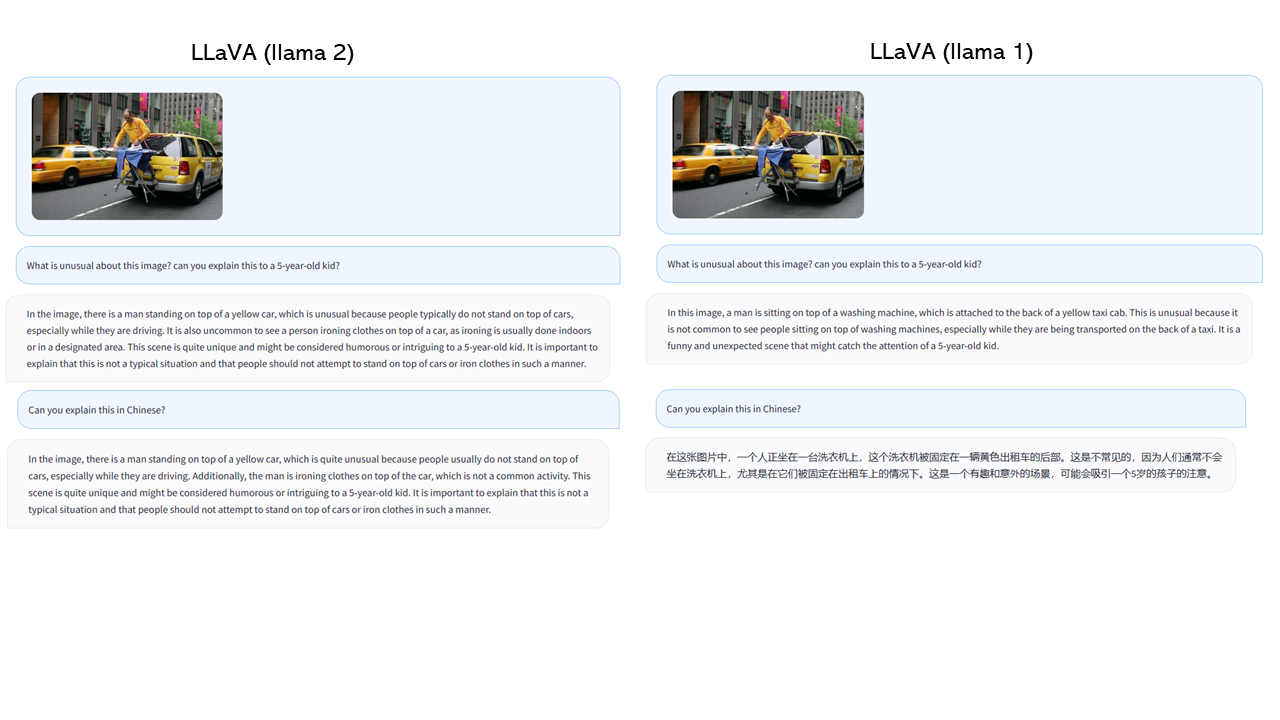
一个面向多模式GPT-4级别能力构建的助手。它结合了自然语言处理和计算机视觉,为用户提供了强大的多模式交互和理解。LLaVA旨在更深入地...
自从扩散模型发布以来,GAN的关注度和论文是越来越少了,但是它们里面的一些思路还是值得我们了解和学习。所以本文我们来使用Pytorch 来...
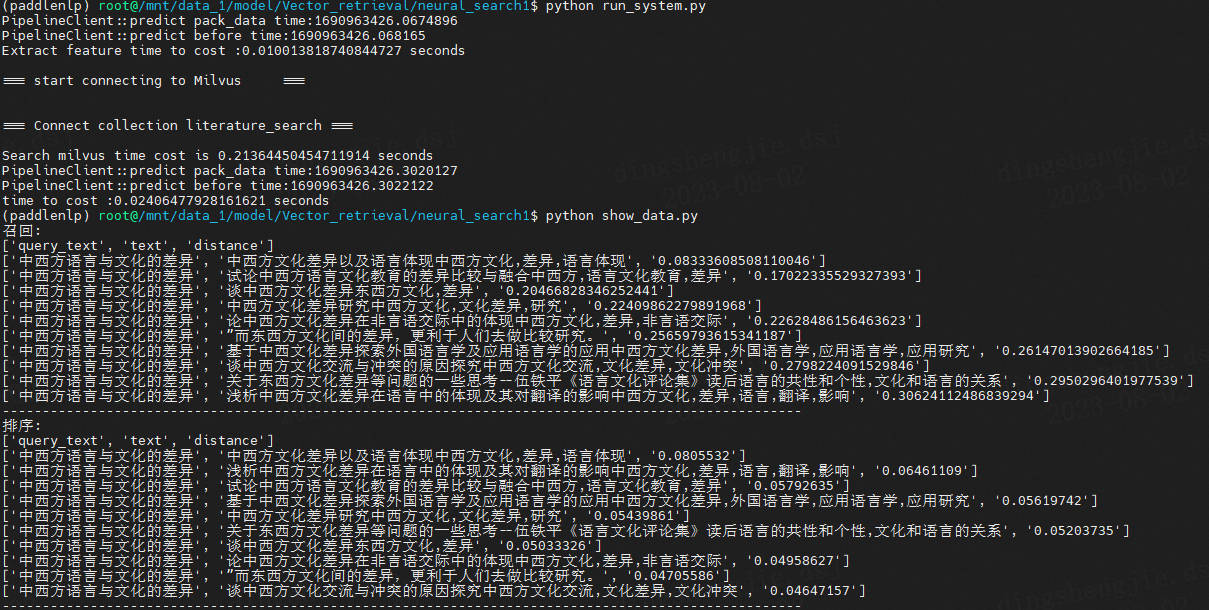
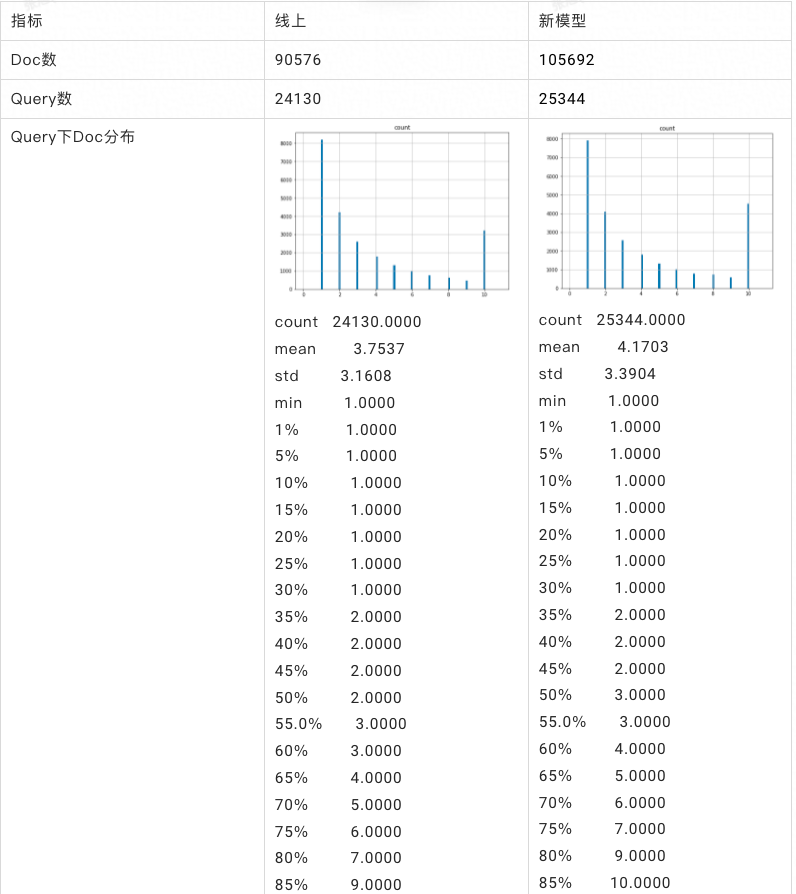
近年来,基于向量进行召回的做法在搜索和推荐领域都得到了比较广泛的应用,并且在学术界发表的论文中,基于向量的 dense retrieve 的方...
如果沿着y轴移动序列添加随机噪声,并随机化这些序列,那么它们几乎无法分辨,如下图所示-现在很难将时间序列列分组为簇:
许多 NLP 任务的成功离不开训练优质有效的文本表示向量。特别是文本语义匹配(Semantic Textual Similarity,如 paraphrase 检测、QA 的...
一个多智能体元编程框架,给定一行需求,它可以返回产品文档、架构设计、任务列表和代码。这个项目提供了一种创新的方式来管理和执行项...
2020年发布的N-BEATS、2022年发布的N-HiTS和2023年3月发布的PatchTST开始。N-BEATS和N-HiTS依赖于多层感知器架构,而PatchTST利用了Tran...
使用多实例GPU (MIG/Multi-Instance GPU)可以将强大的显卡分成更小的部分,每个部分都有自己的工作,这样单张显卡可以同时运行不同的任...
本仓库中的代码示例主要是基于Hugging Face版本参数进行调用,我们提供了脚本将Meta官网发布的模型参数转换为Hugging Face支持的格式,...

虚拟桌宠模拟器:VPet-Simulator,一个开源的桌宠软件, 可以内置到任何WPF应用程序虚拟桌宠模拟器 一个开源的桌宠软件, 可以内置到任何W...

麻省理工学院和香港中文大学推出了LongLoRA,这是一种革命性的微调方法,可以在不需要大量计算资源的情况下提高大量预训练语言模型的上...
这是一篇很有意思的论文,他基于心音信号的对数谱图,提出了两种心率音分类模型,我们都知道:频谱图在语音识别上是广泛应用的,这篇论...
在实际场景中,很多数据集都是多维度的。随着维度的增加,数据空间的大小(体积)会以指数级别增长,使数据变得稀疏,这便是维度诅咒的...

在微信偶然发现聆思科技的CSK6开发板的评估活动,因为经常在各种硬件平台上测试模型,因此申请了测评。很荣幸能被选中。

真实数据集中不同维度的数据通常具有高度的相关性,这是因为不同的属性往往是由相同的基础过程以密切相关的方式产生的。在...
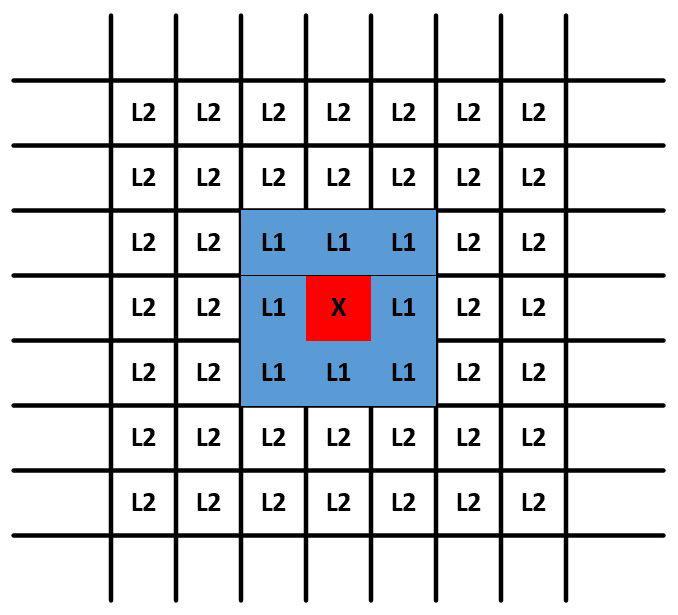
使用QLoRA对Llama 2进行微调是我们常用的一个方法,但是在微调时会遇到各种各样的问题,所以在本文中,将尝试以详细注释的方式给出一些...
ChatGPT对于一些简单的问题,可以完美的完成任务。但是我让它写一篇完整的文章,看看它能否代替我进行写作地的时候,我确定它不能完全取...
汉明距离(Hamming Distance),编辑距离(Levenshtein Distance),欧氏距离(Euclidean Distance),曼哈顿距离(Manhattan Distance)等