尽管 2021 年 2 月 Magic Leap 的首席执行官 Peggy Johnson 透露了二代产品预计于 2021 年第四季度面世,但毫无悬念地迎来了跳票。

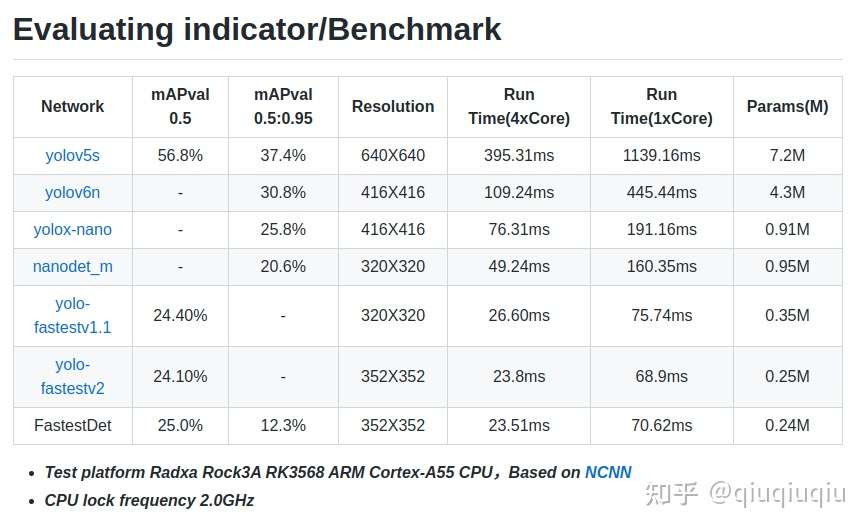
表中耗时是用NCNN测的,测试平台为RK3568 ARM-CPU,FastestDet相比于yolo-fastest单核耗时减少了10%,mAP0.5的指标要比yolo-fastestv2提...
【CPU下12ms】轻量姿态估计模型Regression方法如何做到比Heatmap方法快近3倍且精度更高

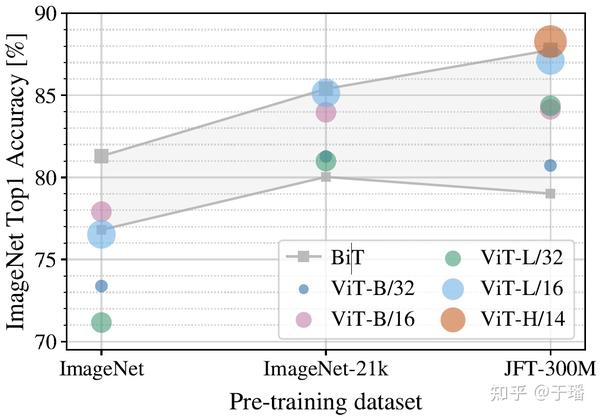
自从Vision Transformer网络面世以来,Transformer模型在CV领域的应用也逐渐开始崭露头角。然而如图1所示,原始的ViT网络模型在小数据集...
据 IDC 2021 年第四季度可穿戴设备全球出货量报告显示,在以智能眼镜、智能戒指等为核心的细分领域,该季度获得了 94.1% 的增长,其中深...

2022年7月,YOLOv7来临, 论文链接:[链接] 代码链接:[链接] 在v7论文挂出不到半天的时间,YOLOv3和YOLOv4的官网上均挂上了YOLOv7的链...

YOLOv7 在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的目标检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时目标...

近日,计算机视觉国际顶级会议 CVPR 的 AI City Challenge 挑战赛(以下简称 AICity)落下帷幕,来自旷视研究院的代表队荣获 Tracked-Ve...

对于视频的生产与消费,其全链路包含采集、制作、管理、分发、消费五个阶段,而云计算和网络的发展,为每个环节都带来巨大的势能变化。

在半月前结束的NBA总决赛中,百视TV作为全网唯一采用“主播陪你看NBA”模式的直播平台,以“陪看型”赛事解说来面对内容差异化竞争。与此同...

图像去噪在二值图像分析、OCR识别预处理环节中十分重要,最常见的图像噪声都是因为在图像生成过程中因为模拟或者数字信号受到干扰而产生...

自去年 10 月 Meta 宣布全力投身元宇宙以来,仅 2022 年第一季度,元宇宙业务就净亏损 30 亿美元,去年全年净亏损更是达到惊人的 100 亿...

最近的 Vision Transformer (ViT) 模型在各种计算机视觉任务中都展示了不错的性能,这要归功于其通过Self-Attention对图像块或Token的远...

ViT正在改变目标检测方法的格局。ViT在检测中的一个自然用途是用基于Transformer的主干替换基于CNN的主干,这直接且有效,但代价是为推...

目标检测是计算机视觉中一项艰巨的下游任务。对于车载边缘计算平台,大模型很难达到实时检测的要求。而且,由大量深度可分离卷积层构建...

作为儿童电话手表的开创者,小天才一直在该领域引领风骚。来自 IDC 中国的数据显示,2018 年 6 月,小天才电话手表累计销量超 1000 万台...

随着Transformer的大火,NLP任务和CV任务的壁垒逐渐被打通。视频分割一直是一项极具挑战的任务,因为它对理解整个视频内容和各种语言概...

在毫无新意的开场后,便是更无新意的 iOS 16 的介绍。锁屏、专注模式、听写、撤回消息、碰一碰支付……这些已经在国产 Android 手机上出现...

在 DETR 出现之后,端到端的目标检测得到了迅速的发展。DETR 使用一组稀疏查询来替换大多数传统检测器中的密集候选框。相比之下,稀疏查...

在自动驾驶系统的设计中,停车位的检测一直是一项具有挑战性的任务。本文将带大家精读2021 CVPR的论文"基于CNN的区域特定多尺度特征提取...









